MVC 패턴이란?


개발자가 웹 페이지를 만드는 걸 생각해보자. 서로 다른 이름을 가진 사용자 수가 3명일 때, 웹 페이지는 총 3개일...수도 있다. 하지만 만약 9999명이 된다면? 사실 100명만 되도, 개발자는 복사 붙이기(일명 복붙)을 100번 해야 하는 셈이다. 이를 해결하고자 MVC 패턴이라는 것을 만들었고, 홈페이지를 보여주는 뷰(View)와, 사용자의 요청을 서버에서 처리하는 컨트롤러(Controller), 데이터를 관리하는 모델(Model) 방식을 만들기 시작했다.

1. 뷰 템플릿 생성하기
이제, MVC 패턴을 인텔리제이 환경에서 실행해 보자. 우선, 머스태치를 활용하여 뷰 템플릿을 만든다. 여기서 머스테치란, 다양한 언어를 화면에 제공하는 템플릿 엔진이라고 생각하면 된다.
src -> resources -> templates -> 우클릭 new -> file 클릭 -> first.mustache 생성


여기서 확장자에 .mustache를 적었음에도 수염과 같은 아이콘 모양이 나오지 않아도 걱정하지 말자.
인텔리제이의 왼쪽 상단에 file -> settings -> plugin -> mustache를 클릭하여 설치해주면 된다.

자, 빈 화면이 나오지 않았는가?
여기서 doc를 누르고 tab 버튼을 누르면, 다음과 같은 html 코드가 자동으로 생성된다.
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
</body>
</html>
head의 <title>태그는 웹 페이지의 제목을 나타낸다. 참고로, 왼쪽에 보이는 네이버의 아이콘은 파비콘이라고 하며, 이것도 설정할 수 있으나 여기서는 생략하겠다! <title> 태그 사이에 내가 원하는 웹 페이지의 제목을 적어보자.

그리고, <body> 태그 안에 <h1> 태그를 달고, 원하는 말을 넣어보자. 필자는 이렇게 했다. 그리고 {{username}}은 변수를 받아오는 형식이다. 이를 통해, 앞서 말했던 '각 사용자 마다 페이지를 만드는 것'을 하지 않고, 원하는 변수만 바꾸어 하나의 페이지에 여러 형식을 보일 수 있다.
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Spring boot 연습</title>
</head>
<body>
<h1>Hell로 월드!!!!</h1>
<h2>{{username1}}님, 스프링 부트 열심히 하셔야죠??</h2>
<h2>{{username2}}님, 네카라쿠배 가야죠~~</h2>
</body>
</html>
2. 컨트롤러
뷰 페이지를 설정했으니, 그 화면을 볼 수 있도록 요청을 처리해주는 컨트롤러를 만들어보자.
com.example.practice 우클릭 -> package -> com.example.practice.controller 입력 -> FirstController.class 생성

package com.example.practice.controller;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
@Controller //이 객체가 컨트롤러임을 알게 해주는 어노테이션
public class FirstController {
@GetMapping("/hi") //URL 요청 접수
public String helloWorld(Model model) {
model.addAttribute("username1", "김철수");
model.addAttribute("username2", "김영희");
return "first"; //first 머스테치 반환
}
}
여기서 @를 사용한 "어노테이션"을 볼 수 있다.
어노테이션이란, 소스 코드에 추가적으로 사용하는 메타 데이터의 일종이다. 코드를 서버에서 어떻게 처리해주어야 하는지 명시해주는 목적으로 사용된다.
@Controller는, 이 객체가 컨트롤러임을 명시한 어노테이션
@GetMapping("/hi")는, Client로 부터 URL을 요청 받았을 때, 아래 메소드가 실행되도록 하는 조회 어노테이션이다.
helloWorld 메서드의 매개변수는 Model로, MVC 패턴의 M을 담당하는 모델이다. 만약 빨간 줄이 뜬다면 alt + enter를 사용하여 import 해주면 된다.
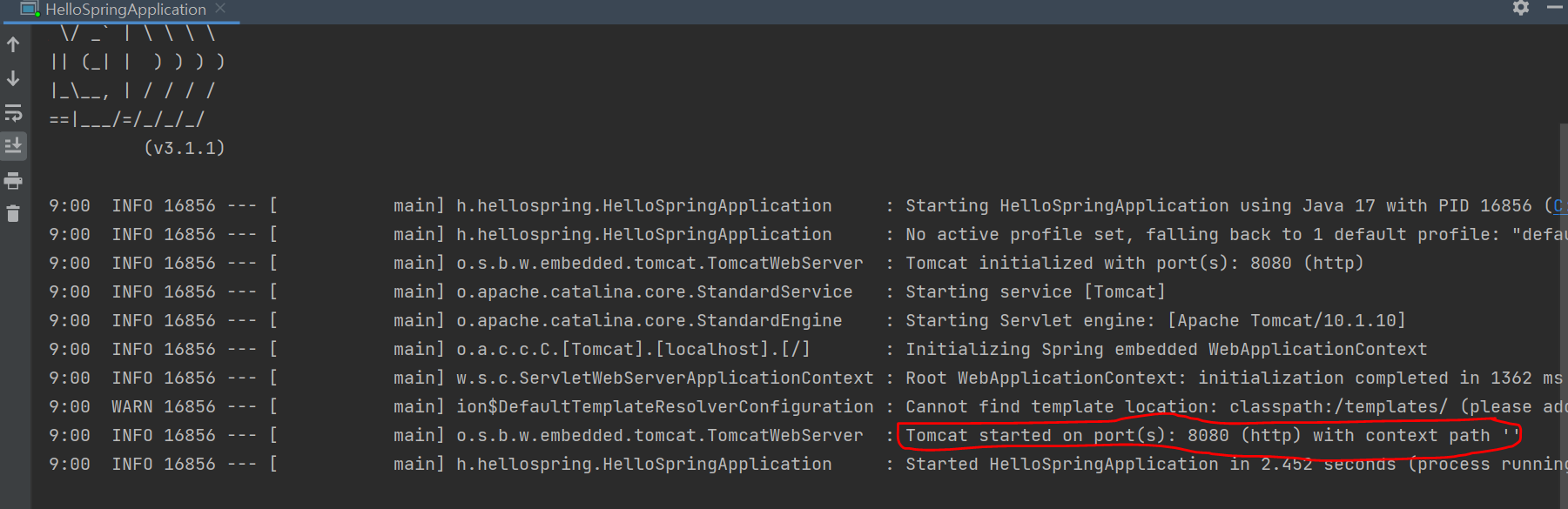
코드를 다 작성하고, 서버를 실행하면 다음과 같은 로그를 볼 수 있는데, Tomcat started on port 8081을 보면 8081 포트에서 서버가 실행된 것을 확인할 수 있다. 그러나 대부분의 사람들은 8080 포트에서 서버가 동작할 것이다. 스프링 부트는 톰캣이라는 것에 담겨서 실행되므로 다음과 같은 로그가 뜬다.

localhost:8081/hi 에 접속하여 내가 원하는 뷰 페이지가 나오는지 확인해보자.
만약 한글이 깨져서 나온다면, src -> main -> resources -> application.properties 파일에서 다음과 같은 코드를 넣어주자.
server.servlet.encoding.force=true

원하는 페이지를 출력한 것을 확인할 수 있다.
'개인 프로젝트 > Java Springboot' 카테고리의 다른 글
| [Java Spring boot] - start.spring.io로 스프링부트 준비하기 (0) | 2024.01.27 |
|---|---|
| 0. 자바 백엔드 개발 입문 - 홍팍 시리즈 선택 (1) | 2024.01.27 |